Using regular expressions to turn a postcode into a UK constituency — purely on the client (no databases). Our developer, John, looks back at some data crunching he did for the 2015 general election
It was ten to seven on a Saturday morning in late March. Curlicues of vapour drifted up from a cup of coffee as I waited for my development environment to boot up. It was a little over a month until the 2015 UK general election.
The day before I had put the final (developer speak, not actually final) touches to a tool that would allow visitors to Channel 4’s “X” campaign site to enter their postcode and see a breakdown of the political parties that had run in the 2010 general election. In essence, it would show by how much of a margin the winning party had won by and the difference a vote, your vote, could make.
The tool itself was, by today’s standards, unimaginative. Searching for a postcode with open data from the Office of National Statistics and the Ordnance Survey was trivial and a far cry from the days of the Post Office holding onto that data like a precious stone (which ironically is about how much it used to cost to purchase access to that data). One REST API call later and a blob of political party JSON was returned to the searcher. Job done, dust off hands, go home.
Only that REST API was a clutch of moving parts. It required a database, at least one web server each with a scripting language interpreter… that was a lot that could go wrong. And things do go wrong, and with a dwindling number of days to go before the site’s launch, testing that setup and infrastructure was a huge investment in time. It had to be robust.
So there I was the next morning, with the question lingering: what if?
What if that unimaginative REST API wasn’t needed and the postcode search could be done all on the client side? It would obviate the need for all those moving parts, but the very idea is lunacy, surely? At the time, there were about 2.5 million unique UK postcodes and 650 parliamentary constituencies. If you were to blob all of that information into, say, a CSV file, it would be over 1GB in total. That’s a staggering amount of data for a desktop browser to parse, let alone a mobile device (and the user’s data plan).
So how to make all that data suitable for web browsers without an external API?
Optimisation, computer science style
So starting with a small sample of data for Sheffield Central, let’s step through how to optimise it.
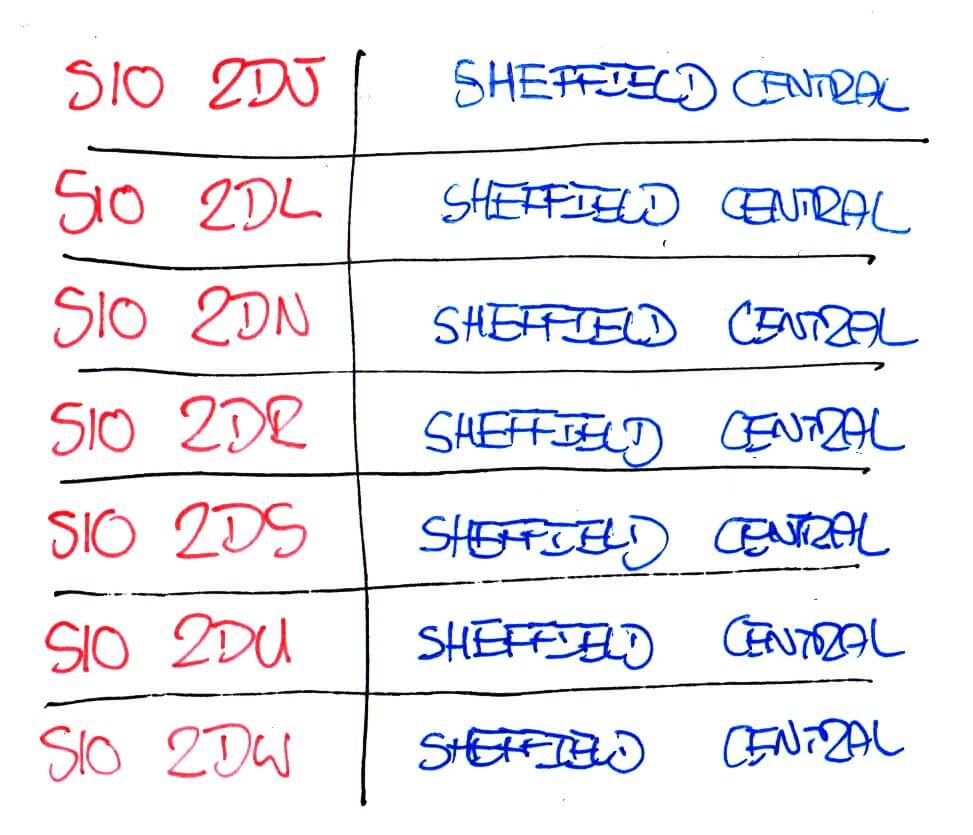
S10 2DJ, Sheffield Central
S10 2DL, Sheffield Central
S10 2DN, Sheffield Central
S10 2DR, Sheffield Central
S10 2DS, Sheffield Central
S10 2DU, Sheffield Central
S10 2DW, Sheffield Central
If we were to send this data as-is, as well as taking a long time to search through — we would have to check every single line to find an entered postcode — there’s a lot of repetition. The first thing to do is change “Sheffield Central” into a number:
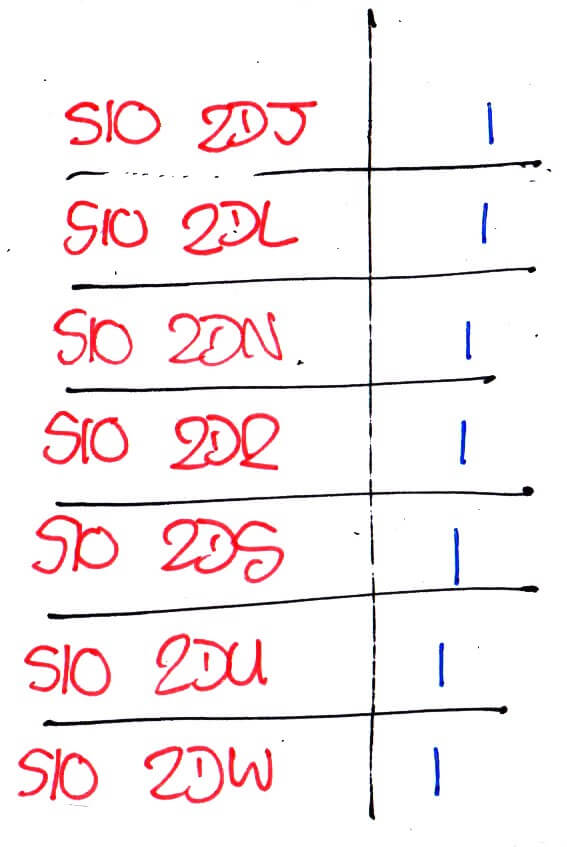
S10 2DJ, 1
S10 2DL, 1
S10 2DN, 1
S10 2DR, 1
S10 2DS, 1
S10 2DU, 1
S10 2DW, 1
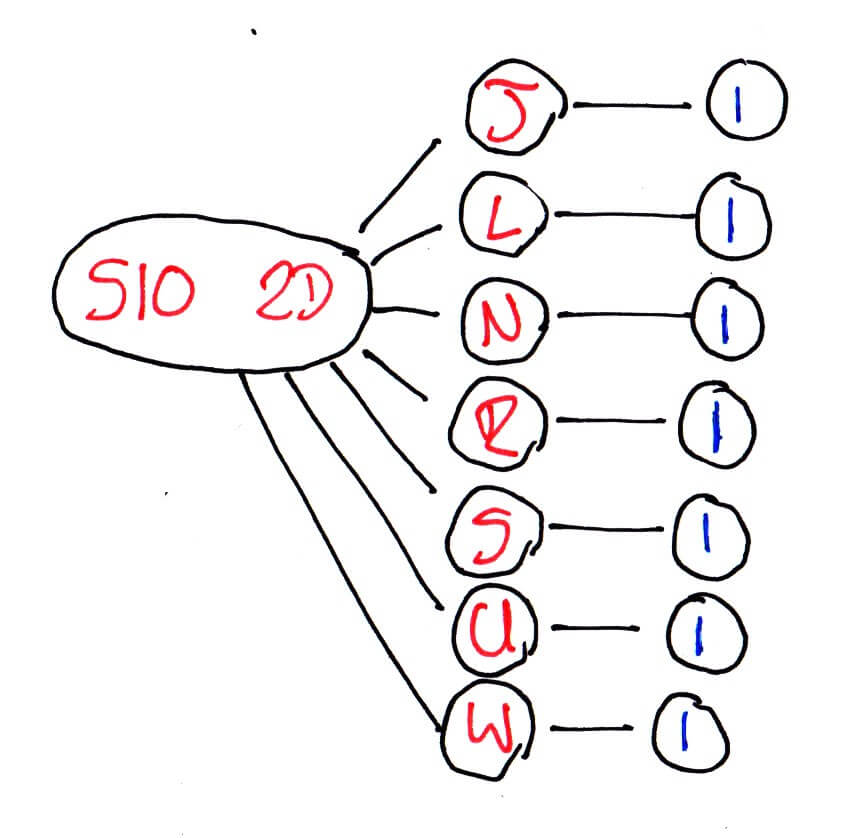
We then only have to send the string “Sheffield Central” once and afterwards can look it up using the number. But there’s still a lot of repetition: we’re effectively sending “S10 2D” seven times which seems wasteful. To optimise this we have to change the structure of the data from the simple to understand table format into a tree:
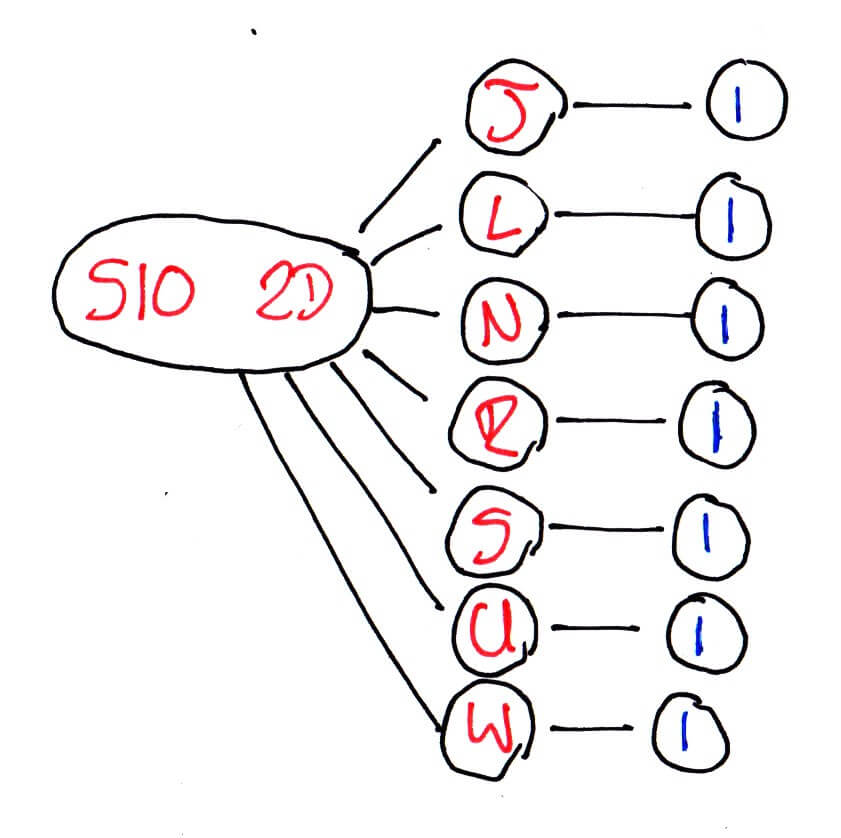
S10 2D -> [J, L, N, R, S, U, W] -> 1
The structure — as well as making me sound like a mad arborist — allows us to infer things about the data that a table didn’t: if someone entered “S10 2D”, there are only seven possible ways to complete that postcode. Obviously our data set is quite small, but with the structured format of postcodes, this way of representing our data becomes very powerful.
Only we’re still kind of repeating ourselves. In our test data we don’t actually need to know how the postcode ends because all roads lead to Sheffield Central:
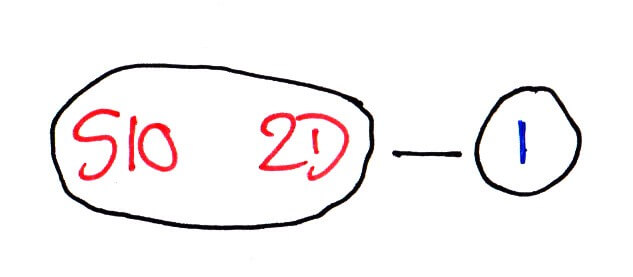
S10 2D -> 1
So we’ve gone from seven lines and 188 characters to one line and 12 characters without losing any information. This kind of optimisation works because we have a very limited “target” set of data — the 650 parliamentary wards. If we had a much larger data set, for instance, the latitude and longitude for each postcode (so called “geocoding”) then this optimisation wouldn’t work as well, if at all.
Scaling this kind of optimisation up from our seven postcodes to 2.5 million nets a huge saving in both size and search speed; so much so that if you break up the data according to the first letter of the postcode, the result is something that can indeed be transferred to a visitor’s web browser and run there with no need for an API.
Success! Call my agent I’m moving to Silicon Valley. Right? It was still Saturday morning, my proof of concept had worked. I took a celebratory shower and then that niggling question formed: but what if?
We need to go smaller
There’s a saying in our office: if you have a problem, regardless of what it is, you can solve it one of two ways. With flexbox. Or with regular expressions. Frontend layout problems? Flexbox. Data integrity issues? Regular expressions. Car got a flat tire? Flexbox (probably).
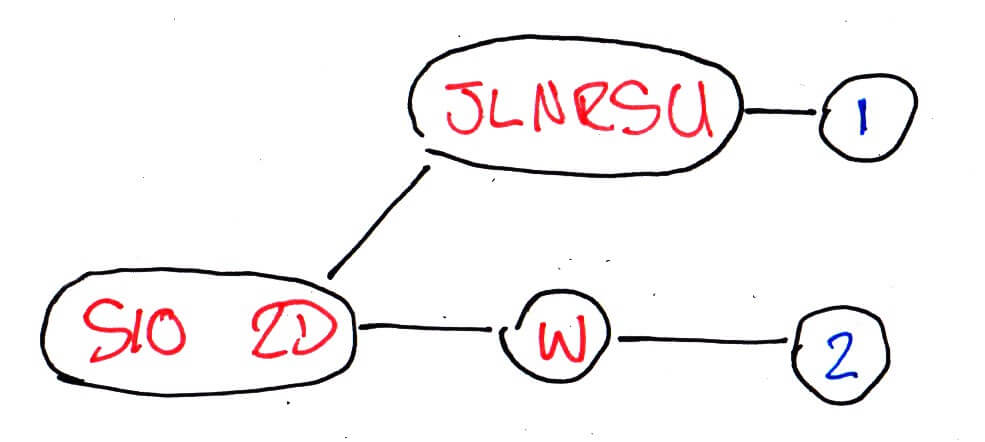
The issue I was seeing with what we had above is that, like Communism, in theory it works brilliantly, but parliamentary constituency boundaries are bonkers in practice. So imagine if all but one of our sample data set ended in Sheffield Central and the other went to Sheffield Hallam? Our optimisation steps would actually end up like:
S10 2D -> [J, L, N, R, S, U] -> 1
-> [W] -> 2
We now have to worry about how all S10 2D postcodes end all because of S10 2DW. Thanks a lot guy. This situation didn’t happen in just one or two constituencies either. This means that more data needs to be stored (and transferred) to retain the same information, and more data means unhappier mobile data plan users.
What to do then? I had a fresh cup of coffee and an attitude of reckless abandon so it was time to start getting silly.
The first thing I did was “collapse” those final, one letter, steps into their own single step:
S10 2D -> JLNRSU -> 1
-> W -> 2
This may not immediately be an obvious optimisation but when the data structure (in this case JSON) is taken into account, the overhead for each additional step makes a huge difference at scale. This step does mean our search becomes slightly more complex, but at just the penultimate step this is manageable. So if more steps mean more overhead, wouldn’t it be easier just to collapse more steps? E.g.
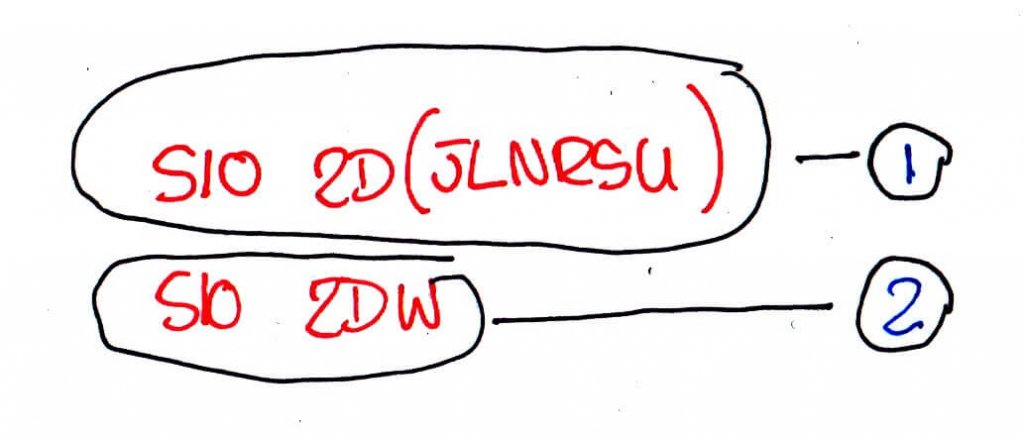
S10 2D(JLNRSU) -> 1
S10 2DW -> 2
At this point our toy data set is becoming less useful as an example, but the sin that I committed is becoming manifest.
It’s alive!
The thing about our office saying is that while flexbox and regular expression are very powerful tools, they are powerful precisely because of their complexity. And because flexbox isn’t going to be any use here (gut feeling), that means I opted for regular expressions.
I created a program that creates regular expressions. I created a monster. A monster that spits out things like:
(1(AE|B[ABDEGHJLNPS-UX-Z]|E[ABD-HJLNP-RTUW-Z]|F[ABL]|G[ADJN]|P[E-HJZ]|Q[ABD-HJLR]|[DJ])|2[ABD-HJLNP-U]|3(A[AE]|B[ABDEHJLNWZ]|D[ABD-HLS-U]|E[BNPQ]|F[NQWX])|5(B[ABDEHJLNP-UW-Y]|D[ABD-FHJLNUWY]|F[BH]|[AE]))
That coincidentally is the regular expression for the S10 postcode for Sheffield Central (link to regexr and regexper).
The grotesque beauty of using regular expressions as well as our tree data structure is that we can tune the regular expressions so that they aren’t unmanageable by a visitor’s browser. Too long an expression and the time it takes to compute it would be a hindrance on under powered devices. Too short an expression and the space saving benefits are lost. So our data structure, with actual data behind it, looks something like:
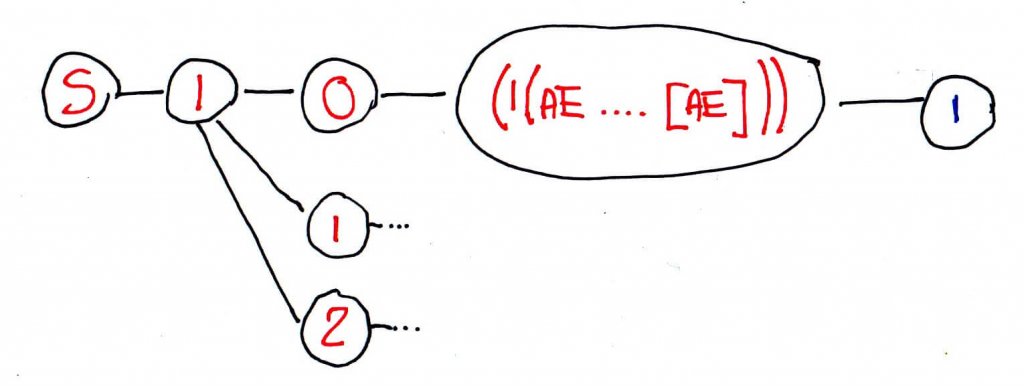
S -> 1 -> 0 -> (1(AE|B[ABDEGHJLNPS-UX-Z]|E[ABD-HJLNP-RTUW-Z]|F[ABL]|G[ADJN]|P[E-HJZ]|Q[ABD-HJLR]|[DJ])|2[ABD-HJLNP-U]|3(A[AE]|B[ABDEHJLNWZ]|D[ABD-HLS-U]|E[BNPQ]|F[NQWX])|5(B[ABDEHJLNP-UW-Y]|D[ABD-FHJLNUWY]|F[BH]|[AE])) -> 1
Results
So what exactly does this… perversion of common sense get us? I’ve steered clear from the numbers behind the optimisation above because it’s easy to become a bit blind when throwing numbers around like frogs at a rocket launch.
But if we take all of the postcodes that begin with an S and transferred a huge CSV (like we started with), the total transfer would be ~3.5MB. After a couple of steps of optimisation with a basic tree structure, the total transfer would be ~1.4MB — a full 41.70673157% of the original. After another step of optimisation and “collapsing” the penultimate level of the tree, the total transfer would be 363KB — only 10.499084982% the size of the original. And then with the final, monstrous regular expression version, the total transfer was ~151KB or 4.3670913387% the size of the original. That last step also includes the constituency information (votes for each party that took party) so isn’t the true size of the postcode data but is the size of the file put into production.
And the “S” postcodes are the largest set, many like “K”, “F” or “Y” barely reach 20KB — smaller than many other assets that go into a modern webpage and smaller still if sent compressed.
The last lap
Sunday afternoon, feeling somewhat unclean about what I had created, I closed my development environment. I was giddy like I’d just done something nefarious, but this would work. It would work, right?
Back in on Monday and sure enough, it worked. Not quite believing it myself, I knocked together a test script that compared every single postcode against the results of the API (authoritative) and the homunculus-like files I had created. No failures. I ran it again just to make sure.
All that was left was integration with the frontend which, thanks to some early use of React, was done in a matter of minutes. For the best possible first-time interaction I also added all of the JSON files as advisory pre-load resources, meaning modern browsers would pre-cache the JSON files so there would be little to no waiting when I requested them (based on the first letter a visitor put into the search box).
Before I even had time to bask in the grimy light of success, the project was live. The client was happy because now the entire site could be hosted on Amazon S3 rather than custom infrastructure and I like to imagine every single visitor to the site marvelled and cooed at how quickly they could search for parliamentary constituencies.
Sure that wasn’t the end of the story — I mean how was I to know the data set I was using didn’t include Northern Ireland postcodes? Or that postcodes could be coded in different ways according to their location (literal edge cases)? But they were minor hiccups in the launch of a much used tool that delivered more than the client asked for and was a (relatively) fun exercise for the developer. As I’ve said before, if something is worth engineering, it’s worth over-engineering.